Пошукові системи оснащені роботами (веб-павуками або ботами), які сканують і індексують веб-сторінки. Якщо ваш сайт або сторінка знаходиться в стадії розробки або містить небажаний контент, роботам можна заборонити сканувати і індексувати ваш сайт. Дізнайтеся, як блокувати цілі сайти, сторінки та посилання за допомогою файлу robots.txt або конкретні сторінки та посилання за допомогою html-тегів&#lt;meta&#gt; &#lt;/meta&#gt; . Читайте далі, щоб дізнатися, як заборонити доступ до контенту певним ботам.
Кроки
Метод1З 2:
Блокування пошукових систем за допомогою файлу robots.txt
Метод1З 2:
 Ознайомтеся з файлом robots.txt. файл robots. txt являє собою простий текстовий файл або файл ASCII, який повідомляє веб-павукам пошукових систем, до яких частин сайту вони можуть отримати доступ. Файли та папки, перелічені у файлі robots.txt, не можуть бути скановані і індексовані пошуковими роботами. Використовуйте файл robots.txt, якщо:
Ознайомтеся з файлом robots.txt. файл robots. txt являє собою простий текстовий файл або файл ASCII, який повідомляє веб-павукам пошукових систем, до яких частин сайту вони можуть отримати доступ. Файли та папки, перелічені у файлі robots.txt, не можуть бути скановані і індексовані пошуковими роботами. Використовуйте файл robots.txt, якщо:- Ви хочете приховати певний контент від пошукових систем;
- Ви перебуваєте в процесі розробки сайту і не готові до сканування та індексації сайту павуками пошукових систем;
- Ви хочете обмежити доступ авторитетним ботам. [1]
-
Створіть і збережіть файл robots.txt. щоб створити файл, відкрийте звичайний текстовий редактор або редактор коду. Збережіть файл як robots.txt. Ім'я файлу має бути написано малими літерами. [2]
- Не забудьте додати» s " на кінці.
- При збереженні файлу виберіть Розширення «.txt». Якщо ви використовуєте Word, виберіть опцію "звичайний текст".
-
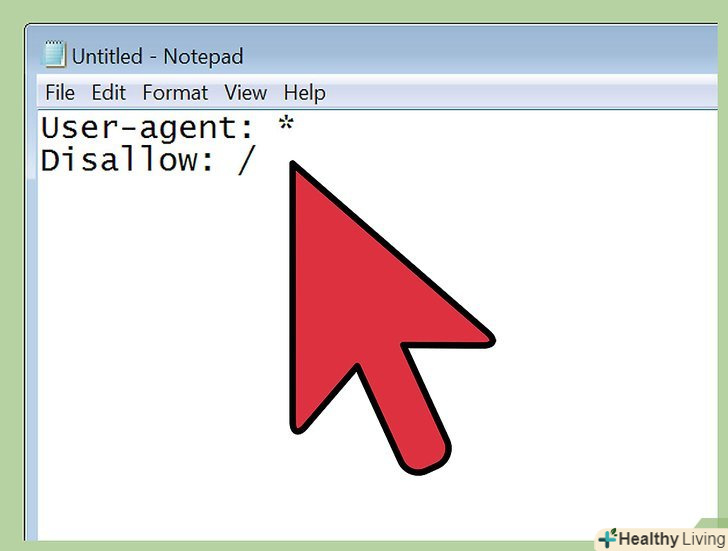
Створіть файл robots.txt з безумовною директивою disallow. безумовна директива disallow дозволить заблокувати пошукових роботів всіх основних пошукових систем, тим самим уникнувши сканування та індексації сайту. Додайте наступні рядки в текстовий файл:
- Використовувати безумовну директиву «disallow» у файлі robots.txt настійно не рекомендується. Коли бот, такий як Bingbot, вважає цей файл, він не проіндексує ваш сайт, а пошукова система його не відобразить.
- User-agents (агенти користувача) — це ще одна назва веб-павуків, або пошукових роботів.
- *: Зірочка означає, що код застосовується до всіх агентів користувача.
- Disallow: /: коса риса вказує, що весь сайт закритий для ботів. [3]
User-agent: * Disallow: /
-
Створіть файл robots.txt з умовною директивою allow. замість блокування всіх ботів, розгляньте можливість блокування доступу конкретних павуків до певних частин сайту. [4] основні команди умовної директиви allow включають::
- Блокування конкретного бота: замініть зірочку поруч зUser-agent на Googlebot , Googlebot-news , Googlebot-image , Bingbot або Teoma . [5]
- Блокування каталогу або його вмісту:
User-agent: * Disallow: /sample-directory/
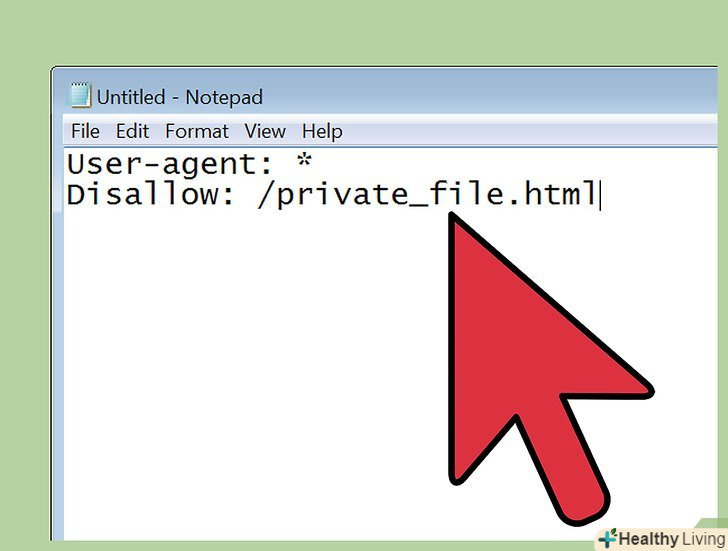
- Блокування веб-сторінки:
User-agent: * Disallow: /private_file.html
- Блокування зображення:
User-agent: googlebot-image Disallow: /images_mypicture.jpg
- Блокування всіх зображень:
User-agent: googlebot-image Disallow: /
- Блокування окремого формату файлу:
User-agent: * Disallow: /p*.gif$
-
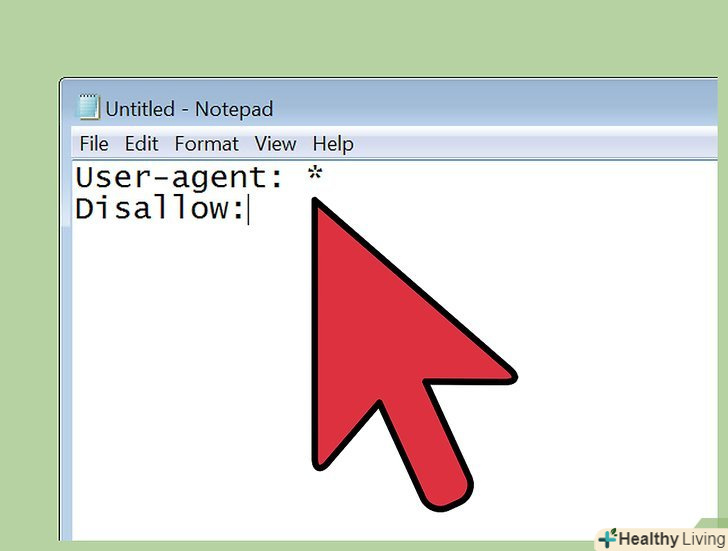
Підстьобніть ботів до індексації та сканування вашого сайту. багато людей не тільки не блокують, а навпаки, вітають увагу павуків пошукових систем до свого сайту, щоб він був повністю проіндексований. Домогтися цього можна трьома способами. По-перше, можна відмовитися від створення файлу robots.txt. Якщо робот не знайде файл robots.txt, то продовжить сканувати і індексувати весь ваш сайт. По-друге, ви можете створити порожній файл robots.txt. Робот знайде файл robots.txt, побачить, що той порожній, і продовжить сканувати і індексувати сайт. Нарешті, можна створити файл robots.txt з директивою безумовного дозволу, використовуючи код: [6]
- Коли бот, такий як googlebot, вважає цей файл, то зможе безперешкодно відвідувати весь ваш сайт.
- User-agents (агенти користувача)-це ще одна назва веб-павуків, або пошукових роботів.
- *: Зірочка означає, що код застосовується до всіх агентів користувача.
- Disallow : порожня команда disallow означає, що всі файли і папки є доступними.
User-agent: * Disallow:
-
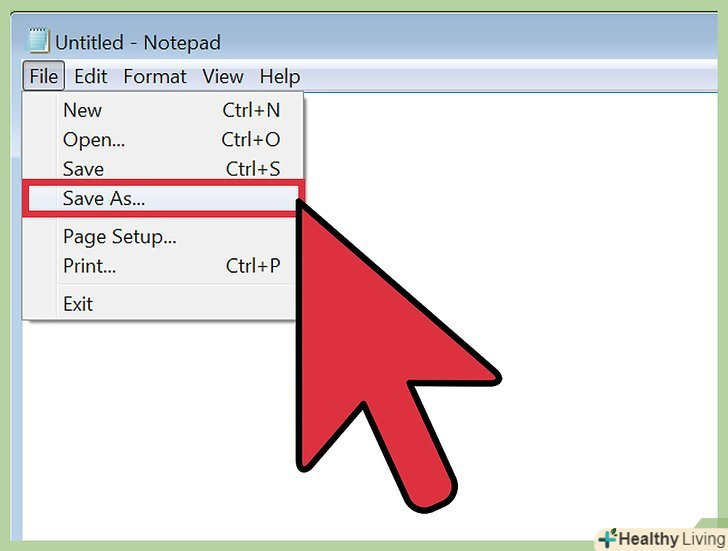
Збережіть текстовий файл у кореневому каталозі домену. після редагування файлу robots.txt збережіть зміни. Вставте файл в кореневий каталог сайту. Наприклад, якщо у вас домен Www.yourdomain.com, помістіть файл robots.txt за адресою Www.yourdomain.com/robots.txt .
Метод2З 2:
Блокування пошукових систем метатегами
Метод2З 2:
-
Ознайомтеся з HTML-метатегом robots. метатег robots дозволяє програмістам встановлювати параметри для ботів або павуків пошукових систем. За допомогою цих тегів ботам забороняють індексувати і сканувати весь сайт або окремі його частини. Також їх можна використовувати, щоб заблокувати певного павука пошукової системи від індексації контенту. Ці теги вказуються в заголовку HTML-файлу. [7]
- Цей метод зазвичай використовується програмістами, які не мають доступу до кореневого каталогу сайту.
-
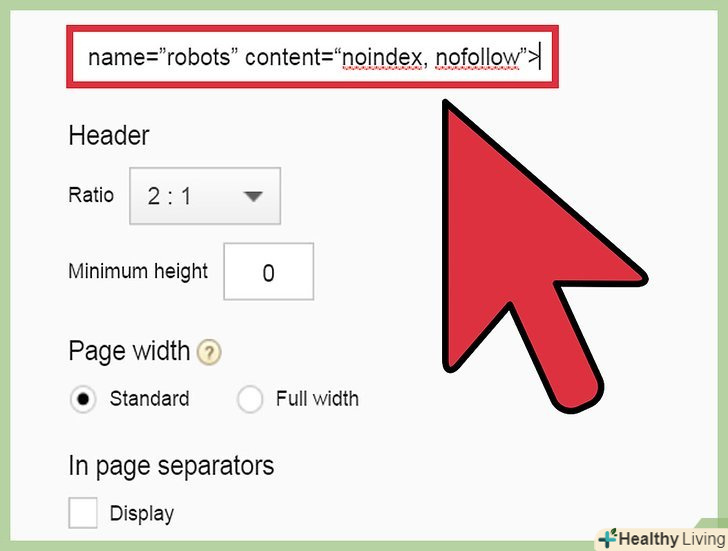
Забороніть доступ ботам до однієї сторінки. індексацію сторінки та / або перехід за посиланнями на сторінці можна заборонити для всіх ботів. Цей тег зазвичай використовується, коли сайт знаходиться на стадії розробки. Після завершення роботи сайту настійно рекомендується видалити цей тег. Якщо ви не приберете тег, сторінка не буде проіндексована або доступна для пошуку через пошукові системи. [8]
- Забороніть ботам індексувати сторінку і переходити по будь-якій з посилань:
&#lt;Meta Name=”robots” Content=“noindex, Nofollow”&#gt;
- Забороніть всім ботам індексувати сторінку:
&#lt;Meta Name=”robots” Content=“noindex”&#gt;
- Забороніть всім ботам переходити за посиланнями на сторінці:
&#lt;Meta Name=”robots” Content=“nofollow”&#gt;
- Забороніть ботам індексувати сторінку і переходити по будь-якій з посилань:
-
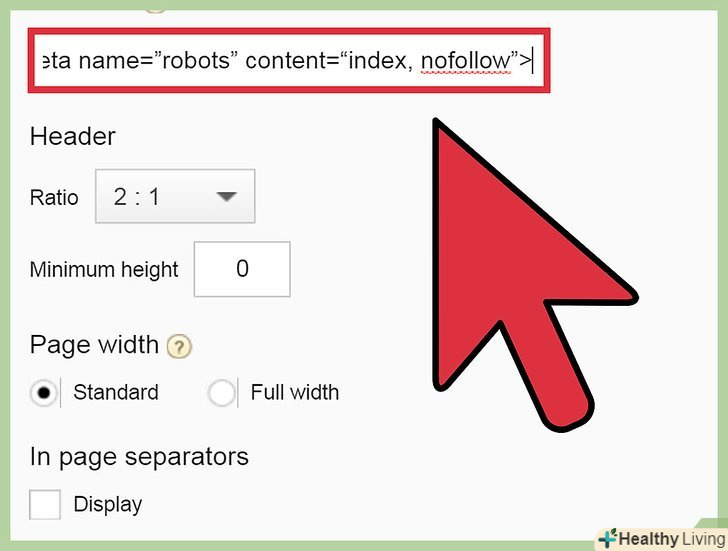
Дозвольте ботам індексувати сторінку, але не переходити по її посиланнях. якщо ви дозволите ботам проіндексувати сторінку, вона буде проіндексована. Якщо ви забороните павукам Переходити по посиланнях, шлях посилання з цієї сторінки на інші буде заблокований. [9] вставте в заголовок наступний рядок коду:
&#lt;Meta Name=”robots” Content=“index, Nofollow”&#gt;
-
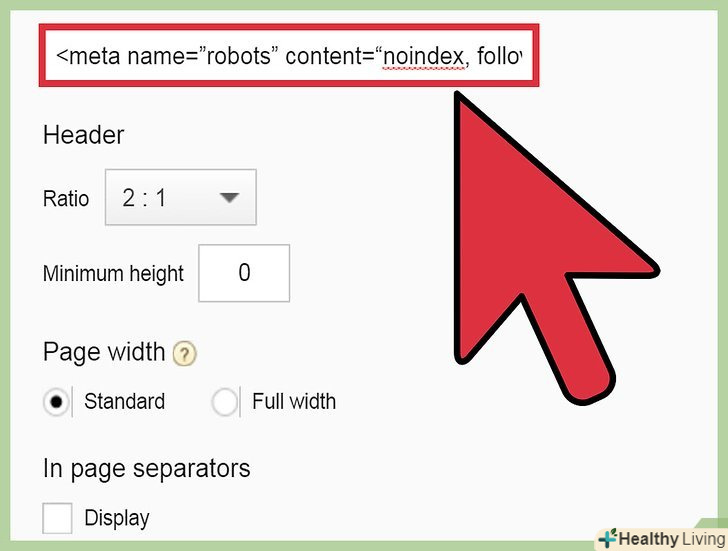
Дозвольте павукам пошукової системи Переходити по посиланнях, але не індексувати сторінку. якщо ви дозволите ботам Переходити по посиланнях, шлях посилання з цієї сторінки на інші залишиться відкритим. Якщо ви забороните ботам індексувати сторінку, вона не з'явиться в індексі. [10] вставте в заголовок наступний рядок коду:
&#lt;Meta Name=”robots” Content=“noindex, Follow”&#gt;
-
Заблокуйте вихідне посилання. щоб приховати одне посилання на сторінці, помістіть тег Rel всередині тега посилання &#lt;a href&#gt; &#lt;/a&#gt; . Використовуйте цей тег для блокування посилань на інших сторінках, які ведуть на конкретну сторінку, яку ви хочете заблокувати. [11]
&#lt;A Href="yourdomain.html" Rel="nofollow"&#gt; Вставте посилання на заблоковану сторінку &#lt;/A&#gt;
-
Заблокуйте конкретного пошукового павука. замість блокування доступу до сторінки для всіх ботів, встановіть заборону на сканування та індексування сторінки лише для одного бота. Для цього замініть слово» robots " в метатезі ім'ям певного бота. [12] приклади: Googlebot , Googlebot-news , Googlebot-image , Bingbot і Teoma . [13]
&#lt;Meta Name=”bingbot” Content=“noindex, Nofollow”&#gt;
-
Підстьобніть ботів до сканування та індексації сторінки. якщо ви хочете переконатися, що сторінка буде проіндексована, а по посиланнях будуть переходити, додайте дозвіл мета-тег «robots» в свій заголовок. [14] використовуйте наступний код:
&#lt;Meta Name=”robots” Content=“index, Follow”&#gt;


Джерела
- ↑ Https://varvy.com/robottxt.html
- ↑ Https://varvy.com/robottxt.html
- ↑ Https://support.google.com/webmasters/answer/6062596?hl=en
- ↑ Https://support.google.com/webmasters/answer/6062596?hl=en
- ↑ Https://www.elegantthemes.com/blog/tips-tricks/how-to-stop-search-engines-from-indexing-specific-posts-and-pages-in-wordpress
- ↑ Https://varvy.com/robottxt.html
- ↑ Https://searchenginewatch.com/sew/how-to/2067564/how-to-use-html-meta-tags
- ↑ Https://searchenginewatch.com/sew/how-to/2067564/how-to-use-html-meta-tags
- ↑ Https://searchenginewatch.com/sew/how-to/2067564/how-to-use-html-meta-tags
- ↑ Https://searchenginewatch.com/sew/how-to/2067564/how-to-use-html-meta-tags
- ↑ Https://css-tricks.com/snippets/html/meta-tag-to-prevent-search-engine-bots/
- ↑ Https://css-tricks.com/snippets/html/meta-tag-to-prevent-search-engine-bots/
- ↑ Https://www.elegantthemes.com/blog/tips-tricks/how-to-stop-search-engines-from-indexing-specific-posts-and-pages-in-wordpress
- ↑ Https://searchenginewatch.com/sew/how-to/2067564/how-to-use-html-meta-tags